
Having characterized storage devices and recognized the important patterns of temporal and spatial locality, we're ready to explore how CPU caches are designed and implemented. While we know that a CPU cache is a small, fast storage device on the CPU that holds a subset of main memory, many challenges still remain, including:
Before we can begin answering these questions, we need to introduce some cache behavior and terminology. Recall that when a program needs to access data in memory, it first computes the data's memory address. Ideally, the data at the desired address is already present in the cache, allowing the program to skip accessing main memory altogether. Thus, the hardware sends the desired address to both the cache and main memory. Because the cache is faster and closer to the ALU, the cache will respond much more quickly than memory can. We call it a cache hit if the data is present in the cache and a cache miss when the data is absent. On a hit, the cache hardware will cancel the pending memory access, since the cache can serve the data more quickly than memory.
On a miss, the program has no choice but to access memory. Critically though, when the request to main memory completes, we load the resulting value into the cache so that subsequent accesses (which are likely thanks to temporal locality) will be serviced from the cache. Even if the memory access that misses is writing to memory, we still load the value into the cache on a miss because it's likely that the program will attempt to read from the same location again in the future.
Often, when we go to load a value into the cache, we find that the cache doesn't have room to store the new value. In such cases, we must first evict some data that is resident in the cache to make room for the new data that we're loading in. As we'll see in detail below, when evicting data that has been modified, the cache may need to perform a write to memory to synchronize their contents before it can load the new value.
In designing a cache, we want to maximize the hit rate to ensure that as many memory requests as possible can avoid going to main memory. While locality gives us hope for achieving a good hit rate, we generally can't expect to reach 100% due to a variety of reasons:
Our characterization of cache misses illustrates that cache performance depends on program behavior. When designing a cache for a general-purpose CPU, we need to make design decisions that will achieve good performance for most programs, acknowledging that no single design will be perfect for every program. Many design parameters exhibit an explicit trade-off that must be balanced.
In this section, we'll start with an empty chunk of cache memory and slowly shape it into functional cache. Our primary goal will be to determine what we need to store in the cache (e.g. metadata in addition to the data itself) and where we want to store the data.
Supposing our cache starts as a shapeless chunk of storage, how should we divide it up? A cache's block size determines the smallest unit of transfer between the cache and main memory. Increasing the block size improves performance for a program that exhibits good spatial locality because many accesses will be nearby those in an already loaded block. However, given a fixed-capacity cache, as cache blocks get larger the cache will have fewer cache lines, or storage locations within the cache. Having fewer cache lines makes conflict misses more likely. At the extreme, you could imagine using the entire cache as a single block, which would cause every cache miss to be a conflict miss! Figure NNN illustrates the trade-off between the block size and the number of cache lines (rows in the table). A typical CPU cache uses block sizes ranging from 16 - 64 bytes.
Next, we need a mechanism for locating data in our cache. In other words, if we're looking in a cache to see if it holds the data we need, which line(s) do we need to check? Alternatively, if we're loading data from main memory into our cache, which lines is it eligible to be stored in? Intuitively, having more storage location options reduces the likelihood of conflicts but also reduces performance due to more locations needing to be checked.
There are three common cache designs to help us answer these questions:
For caches that aren't fully associative, the cache needs to quickly and deterministically map a data block to a single cache location. To solve this problem, we use a portion of the data block's main memory address to choose where it should go in the cache. Ideally, the data blocks will be evenly spread around the cache to reduce conflicts. Thus, caches typically use bits taken from the middle of the data's memory address, known as the index portion of the address, to determine which location it maps to. Using the middle of the address reduces conflicts when program data is clustered together, which is often the case.
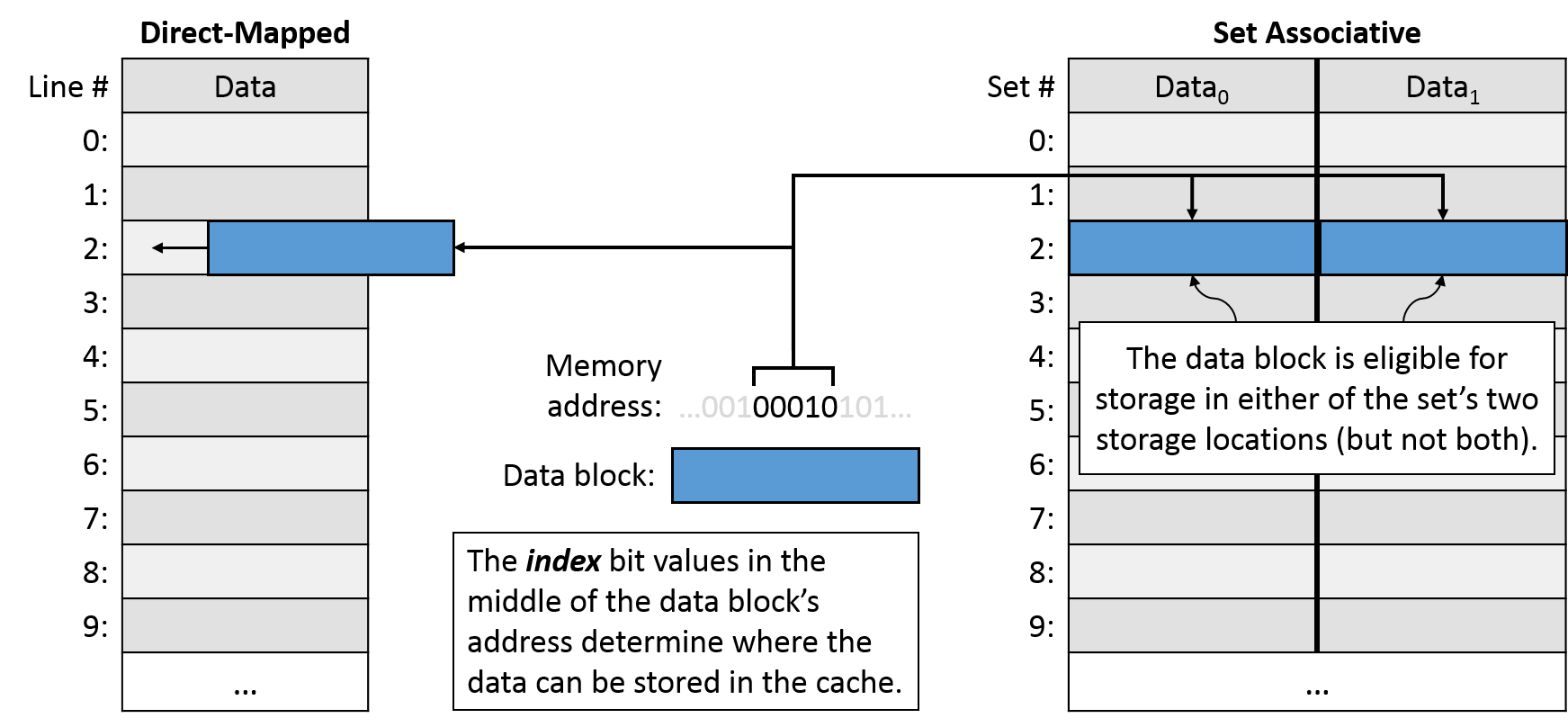
Figure NNN depicts the cache storage location options and address mapping for a data block in the direct-mapped and set associative designs. Moving forward in our exploration of cache designs, we'll proceed with direct-mapped caches due to their relative simplicity. Later, we'll reintroduce set associativity and see how it affects cache behavior.
Another important feature we need from our cache is a mechanism for identifying the contents of each cache line. First, we need to recognize which lines in the cache are not storing a valid data block. Such lines are effectively free space in the cache. Hence, we add an extra valid bit to each cache line to indicate that the line is either currently storing a valid block (valid set to 1) or currently free (valid set to 0). Note that the valid bit is our first example of cache metadata, or information that our cache stores about it's contents as opposed to data from main memory. We'll further augment our cache with additional metadata soon.
When performing a lookup into a cache, an invalid cache line can never produce a hit because it isn't currently storing a subset of main memory. On the other hand, a valid cache line does represent a subset of main memory, so we'll additionally need to determine which subset of memory it's holding. Since main memory already assigns an address to each byte of storage, and programs are already issuing memory accesses based on those addresses, we'll need to extend each cache line with metadata to identify the address of the data it's storing.
Thus, in addition to using the middle portion of the address as an index for selecting a cache line, we'll designate the high-order bits of the address as a tag. The tag serves as a prefix for the stored data block. The tag field allows a cache line to track where in memory its current data block came from. In other words, because many memory blocks map to the same cache line (those with the same index bits), the tag records which of those blocks is present. Figure NNN portrays a direct-mapped cache expanded with a valid bit and tag field.

For a cache lookup to succeed in producing a hit, the tag field stored in the cache line must exactly match the upper bits of program's requested memory address. Upon determining that we have a cache hit, we know the cache's data block is storing the value our program wants. However, the data block's size (e.g., 64 bytes) is typically much larger than the amount of data that the program was requesting (e.g., 4 bytes). We'll use the low-order bits of the requested address as an offset into the cached data block.
Therefore, when a program performs a lookup, we divide the program's requested memory address into three regions, from left (high-order bits) to right (low-order bits): a tag to identify the block, an index into the cache, and an offset within the data block. Putting the entire sequence together, when a program performs a cache lookup on an address, it performs the following sequence of operations:
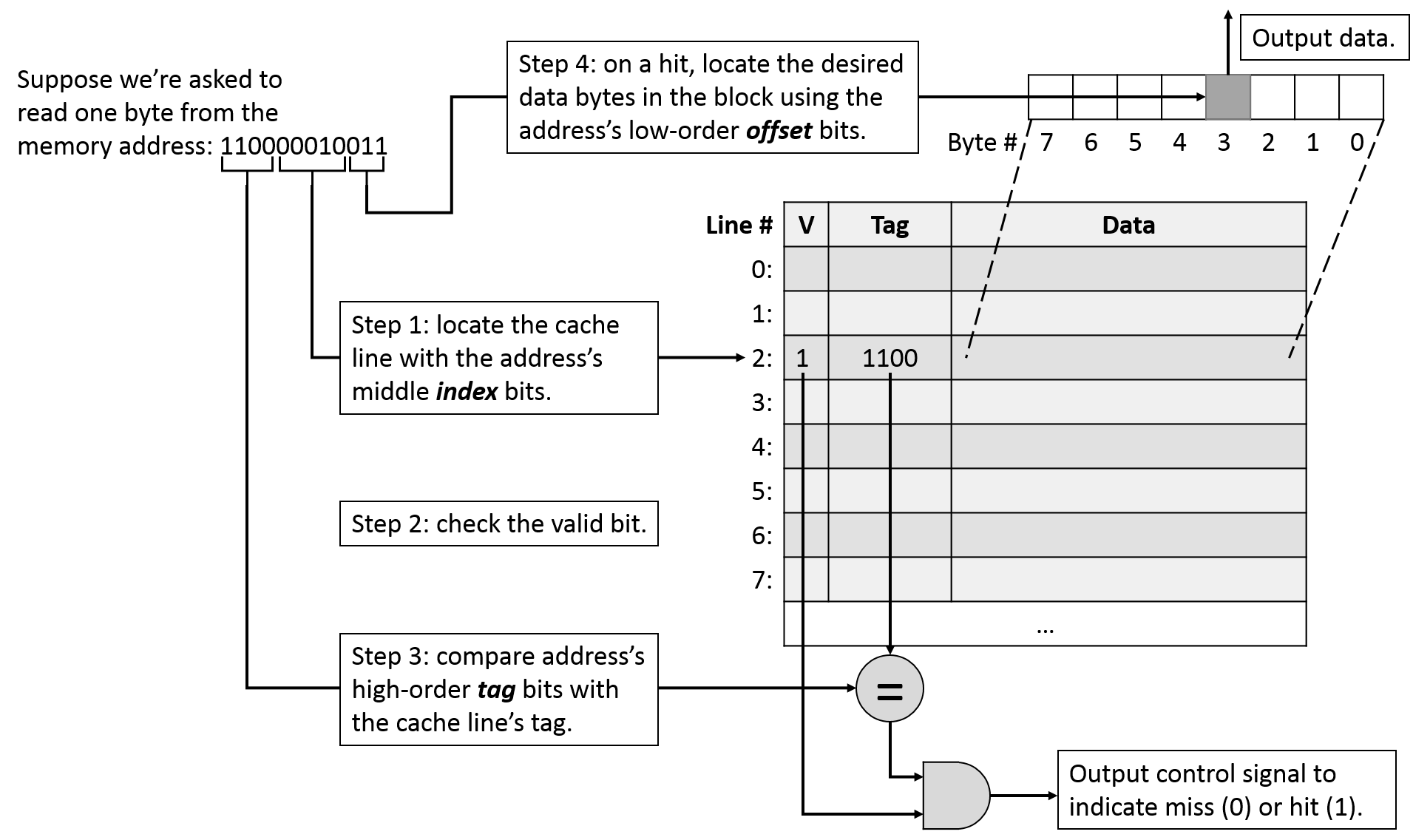
Figure NNN illustrates this lookup sequence with an example address. For now, assume we're dividing up the address into the tag, index, offset portions appropriately. Later, we'll see how changing cache parameters will affect the address division.
So far, we've mainly been considering memory read operations, for which we perform lookups in the cache. What should happen when a program attempts to store a value in memory? Our cache has two options when a program performs a write:
The trade-off between write-through and write-back caches is essentially simplicity vs. performance. By always synchronizing memory immediately, the write-through cache avoids storing extra metadata, but it comes at the cost of performing unnecessary writes to memory. For example, suppose a program repeatedly updates the same variable without it ever being evicted from the cache. A write-through cache will write to memory on every update, even though each subsequent update is just going to overwrite the previous one.
Because caches exist primarily to improve performance, most modern caches opt for a write-back design. In a write-back cache, only the final update to a cache block gets written to memory, and it costs only a small amount of additional metadata per cache line. Figure NNN shows an extension of our cache model with a dirty bit to mark lines that need to synchronize with memory upon eviction.

Up until now, we've been using vague descriptions of memory addresses like "the index comes from the middle bits." How do we define "middle"? In reality, it's important that we be precise in aligning the bit positions of a memory address with their respective roles in the cache. Because the parameters of a cache need to be decided before the cache is built, we can use those parameters to determine how many bits to use for each portion of the address. Alternatively, if given the number of bits in each portion of an address, we can determine what the parameters of a cache must be.
In determining what the bits of an address mean, it's helpful to consider the address from right to left (i.e., from least to most significant bit). The rightmost portion of the address is the offset, which corresponds to the cache's block size parameter. The offset must be able to refer to every possible byte within a cache block, so we need to assign enough of an address's rightmost bits to enumerate every byte within a block. For example, suppose a cache has a block size of 32 bytes. Because a program might come along asking for any of those 32 bytes, we need enough bits in our offset to describe exactly which byte position the program wants. In this case, we would need 5 bits for our offset because log2 32 = 5. In the reverse direction, if you were told that a memory address was using 4-bit offset, that tells you the block size is 2 4 = 16 bytes.
The index portion of the address begins immediately to the left of the offset. To determine the number of index bits, we need to know the number of lines in the cache, since we need enough bits in the index to enumerate every cache line. Using similar logic to the offset, if we're told that a cache has 1024 lines, there must be log2 1024 = 10 bits of index. Likewise, if the number of index bits is given as 12, the cache will have 2 12 = 4096 lines.
All that's left now is the tag. Because the tag must uniquely identify the subset of memory contained within a cache line, the tag must use all of the remaining, unclaimed bits of the address. For example, if you have a machine with 32-bit addresses and you already know that the address is using 5 bits for the offset and 10 bits for the index, the remaining 32 - 15 = 17 bits of the address must all make up the tag portion.
Having explored the parameters of caches and their associated design trade-offs, we're ready to see some examples. Suppose you're given a CPU with the following characteristics:
Suppose your program attempts to access the following memory locations:
To get started, we first need to determine how to interpret those memory addresses. A 32-byte block size tells us that the rightmost five bits of the address (log2 32 = 5) comprise the offset portion. Next, having 128 cache lines suggests that we'll use the middle seven bits of the address (log2 128 = 7) as the index. That leaves the four most significant bits left over for the tag. Assuming we start with an empty cache (all lines invalid), we'll walk though how the cache changes as we perform each memory access.
For the first access (read 1010000001100100), we begin by dividing the address into its tag (1010), index (0000011), and offset (00100). We then index into cache line 0000011 (3) and check the valid bit, which is 0. Because it's invalid, this access is a cache miss, so we need to load the value from memory into the cache. This is an example of a compulsory miss, since there's no way could have had this value already in our cache, we just started!
When we load the value from memory, we must set the tag to indicate where the value came from. We also need to make the line as valid, since it now contains a valid subset of main memory. Note that from the cache's perspective, the contents of the data don't matter, so the value of the data block isn't particularly interesting for example purposes. As long as the cache returns the correct data based on the offset portion of the address, the requesting program will be happy.

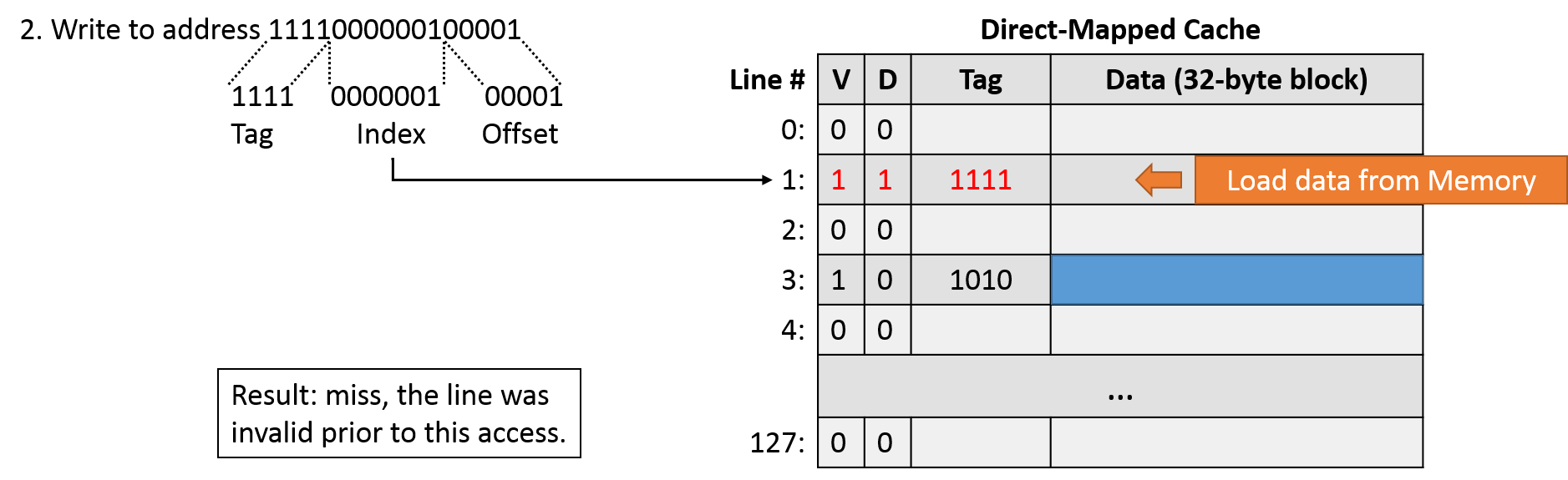
For the next access (write 1111000000100001), we divide the address into a tag (1111), index (0000001), and offset (00001). This is an access to line 1, which is also invalid, so we have another miss. Despite this being a write operation, we still need to load the cache from main memory because the write isn't going to change all 32 bytes of the cache block. Just like the last operation, we need to update the tag and valid bit. Because this is a write, we also need to set the dirty bit to indicate that the cached data is no longer in sync with main memory.
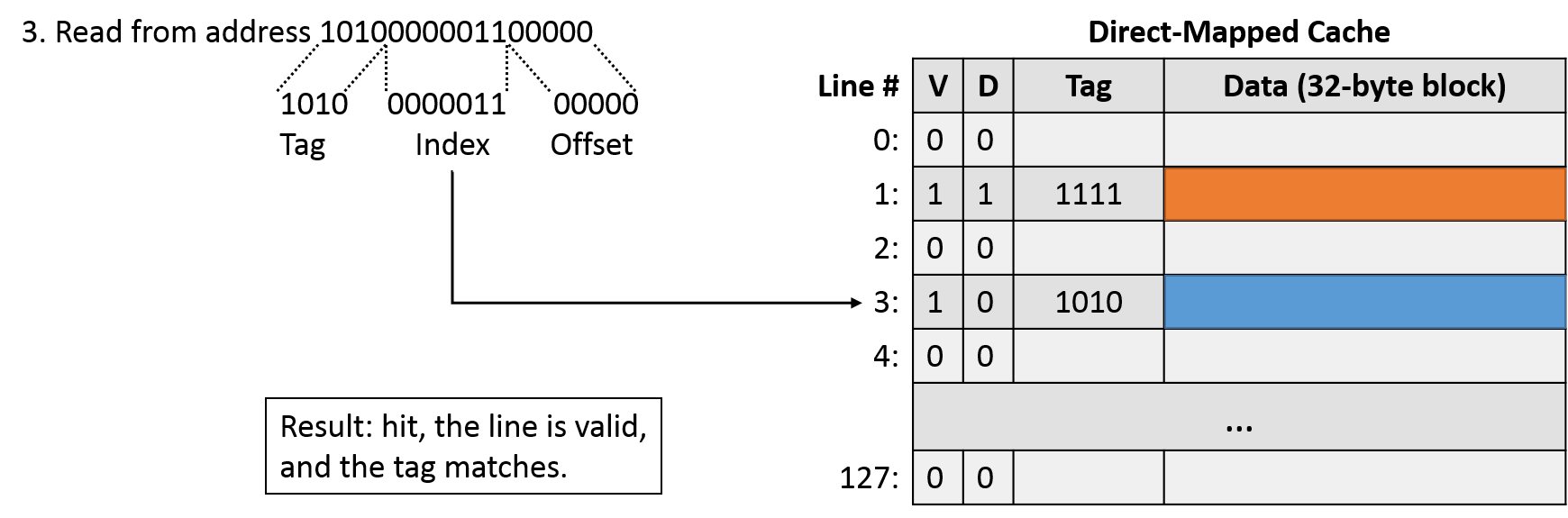
The third access (read 1010000001100000) breaks down into a tag of 1010, index of 0000011, and offset of 00000. Indexing into line 3, we find a valid line, so we need to compare the tag. The tag is a match, so this is a cache hit! Note that the offset isn't the same as the first access, which loaded this memory block into the cache. The change in offset with a matching tag and index suggests that the program is taking advantage of spatial locality.
The next access (read 1111000000111100) yields a tag of 1111, index of 0000001, and offset of 11100. Indexing into line 1 shows a valid entry with a matching tag, so this access is another cache hit.
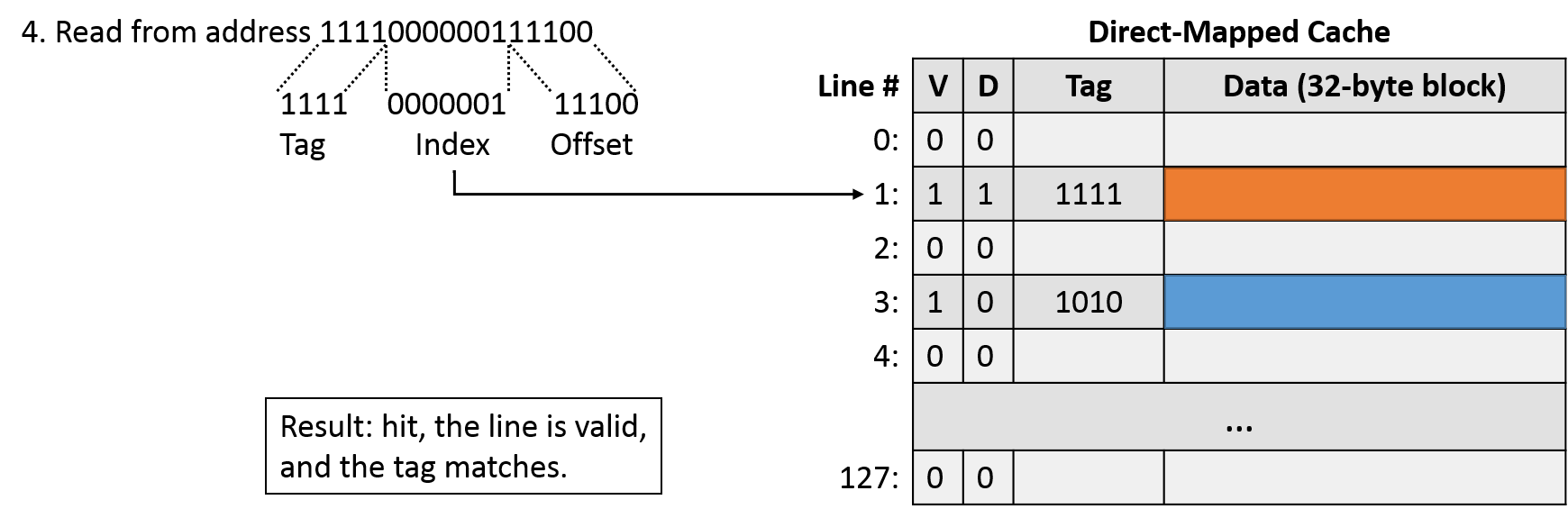
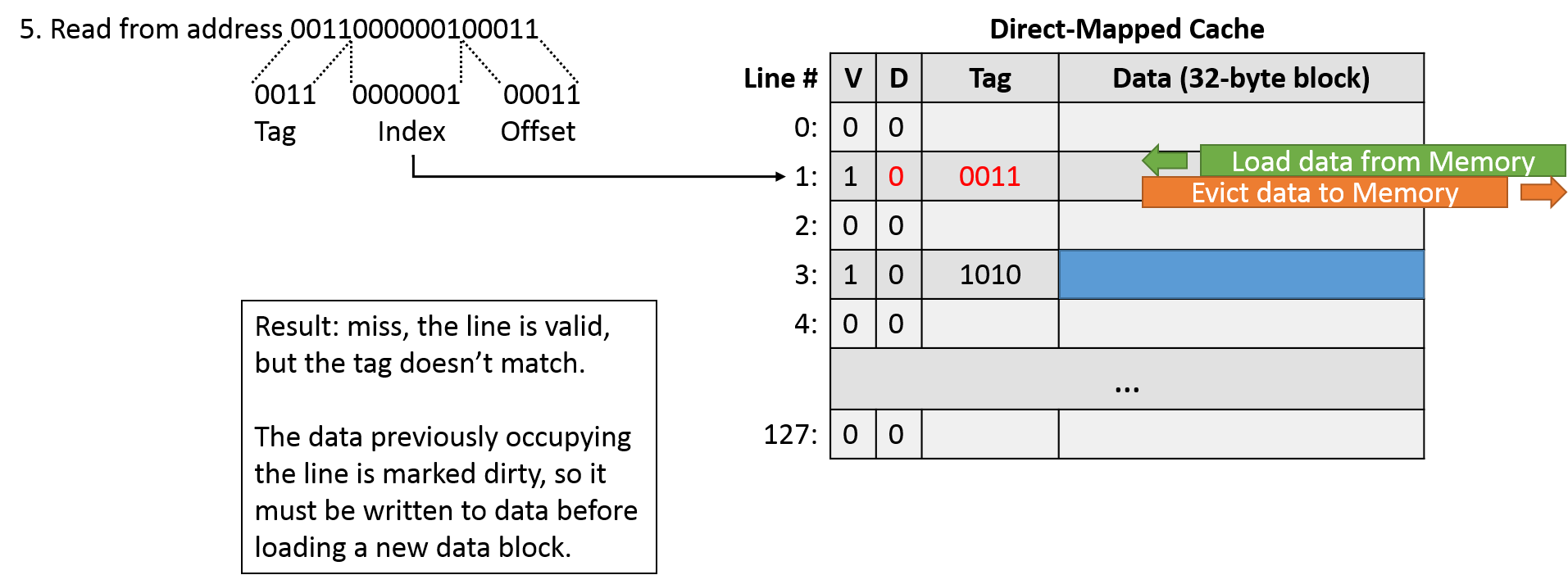
Our final access (read 0011000000100011) corresponds to a tag of 0011, index of 0000001, and offset of 00011. Indexing into the cache, we find line 1 to be valid. When checking the tag, we see that it does not match. This is an example of a conflict miss: the cache is largely empty, but two addresses that our program wants to use both happen to map to the same cache line.
Thus, we need to evict the data that currently occupies the cache to make room for the data we're now accessing. Before we can just overwrite the cached data, we need to check the dirty bit. In this case, because the dirty bit is 1, we must write the stored data out to memory first to synchronize their contents. After the write completes, we can load the new data into our cache line, unset the dirty bit, and update the tag, and proceed as normal with the next instruction.
Note that to show interesting cases in our example, we considered addresses that mapped to just two cache lines. Real programs would (hopefully) take advantage of many more available cache lines.
Now that we're comfortable with direct-mapped caches, let's revisit set associativity. Recall that a set associative cache reduces the negative impact of conflicts by allowing a block to occupy more than one location within a set. Our direct-mapped example saw an unfortunate conflict miss, so let's see if we can modify our cache to make it set associative and solve that problem!
For simplicity in our example, let's say our CPU cache is two-way set associative, which means that at each line of the cache, we have a set of two locations that can store data blocks. While having the additional flexibility of two choices is beneficial for reducing conflicts, it also introduces a new wrinkle: when loading a value into our cache (and when evicting data already resident in the cache), we must decide which of the two options to use!
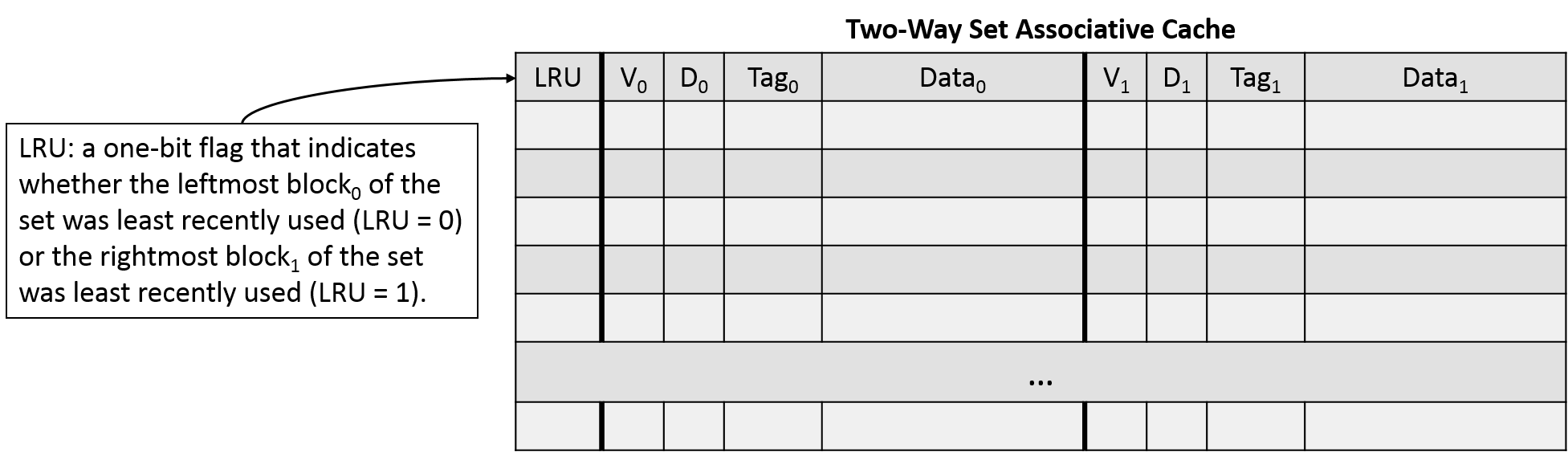
To help us solve this selection problem, we'll return to our old friend, locality. Specifically, temporal locality suggests that data that has been used recently is likely to be used again. Therefore, we'll adopt the same strategy that we used in managing our bookcase: if we need to evict a data block from a set to make room for a new one, we should choose to evict the least-recently used (LRU) block. Figure NNN illustrates a two-way set associative cache with an LRU bit to keep track of which block within each set was least recently used.
 or the rightmost block of the set was least recently used (LRU = 1)." />
or the rightmost block of the set was least recently used (LRU = 1)." />
The decision to use LRU is known as a cache replacement policy, and it requires us to keep track of additional metadata within each set so that we can identify which block was used least recently. Since we have only two options in our two-way set associative cache, we can get away with using just a single additional LRU bit, where 0 means one of the two options was least recently used, and 1 means the other was. For caches with higher associativity (more storage options per set), we need more bits to encode the usage history to accurately track the LRU status of the set. These extra metadata bits contribute to the "higher complexity" of set associative designs.
Returning to the example, let's modify our CPU's characteristics:
Suppose your program attempts to access the following memory locations:
Note: The first three accesses are a subset of the direct-mapped example above.
To begin, we once again need to determine how our addresses will be divided. The block size hasn't changed, so we'll still use five bits for the offset. We now have half as many cache lines, so we need one fewer index bit, giving us six index bits. The remaining five bits constitute the tag.
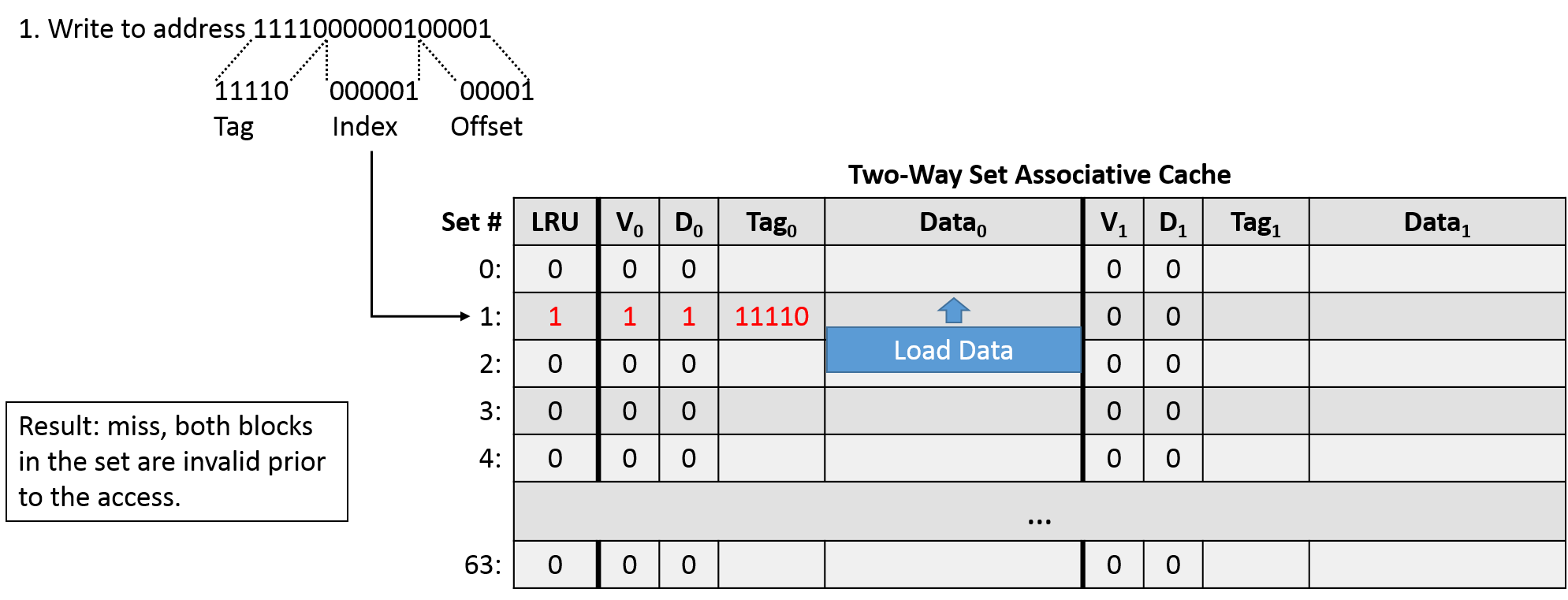
The first access (write 1111000000100001) indicates an offset of 00001, an index of 000001, and a tag of 11110. Indexing into set 1, we find both blocks to be invalid, so we have a cache miss. The LRU bit is set to 0, indicating that the left block is least recently used, so we'll load the block from main memory into that location. (Since both blocks are invalid, it doesn't really matter which side we choose, but for consistency, we'll do what the LRU bit suggests.)
After loading the block from main memory into the cache, we need to update the metadata: the left block's tag must be set, and the valid and dirty bits need to be set to 1. We also need to update the LRU bit to 1, since the right block of the set is now least recently used.
The next access (read 1111000000111100) should be interpreted as an offset of 11100, index of 000001, and tag of 11110. Indexing into the first set, we must check both blocks. The right side is invalid, so it can't possibly be a hit. The left is valid, and checking the tag, we find a match. Thus, the left block is a hit, and the cache would serve the requested value without intervention from main memory. Because we're accessing the left side, we also need to set the LRU bit to 1 (unchanged) to indicate that the right is least recently used.
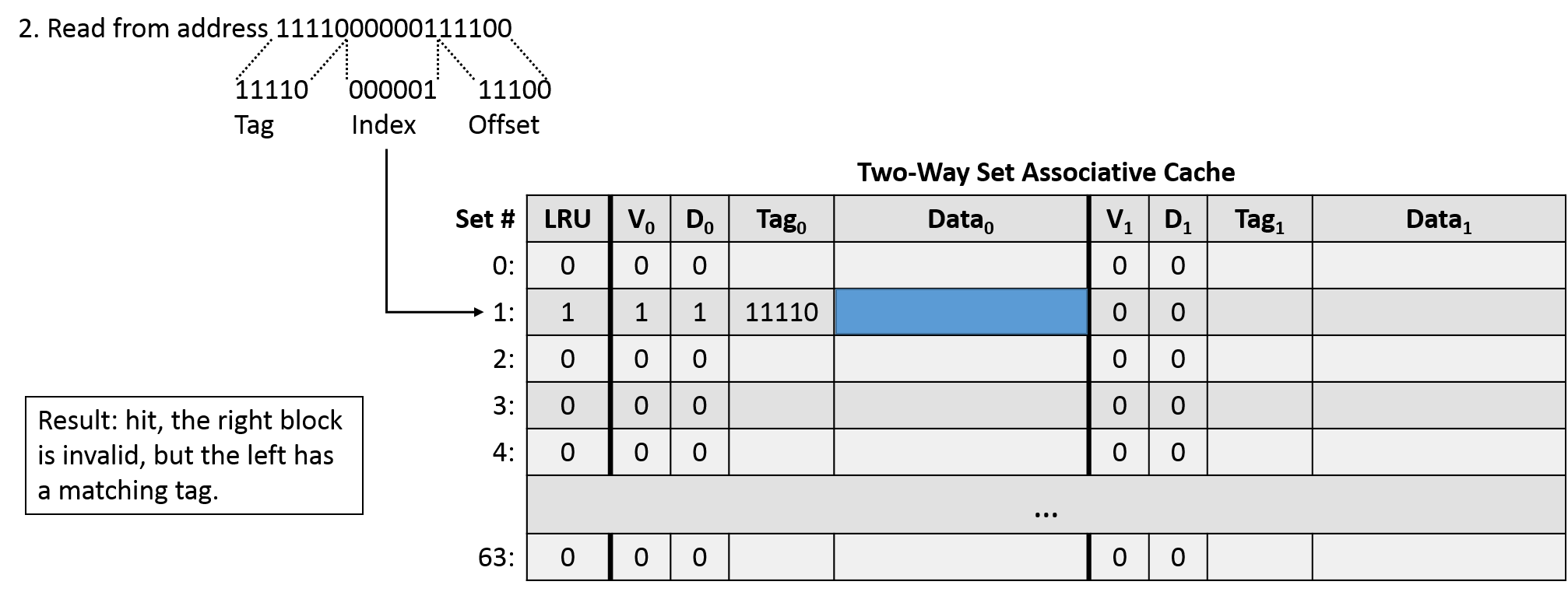
The third access (read 0011000000100011) suggests an offset of 00011, an index of 000001, and a tag of 00110. Indexing into set 1, we find that the right side is invalid and the left's tag doesn't match, so this access is a miss. In our direct-mapped cache, this access caused a conflict that forced us to evict a block from the cache. This time, our LRU bit is 1, so we load the block from main memory into the right block of the set. We need to update the right block's metadata with the tag and valid bit, and we also need to change the set's LRU bit back to 0, since the left side is now least recently used.
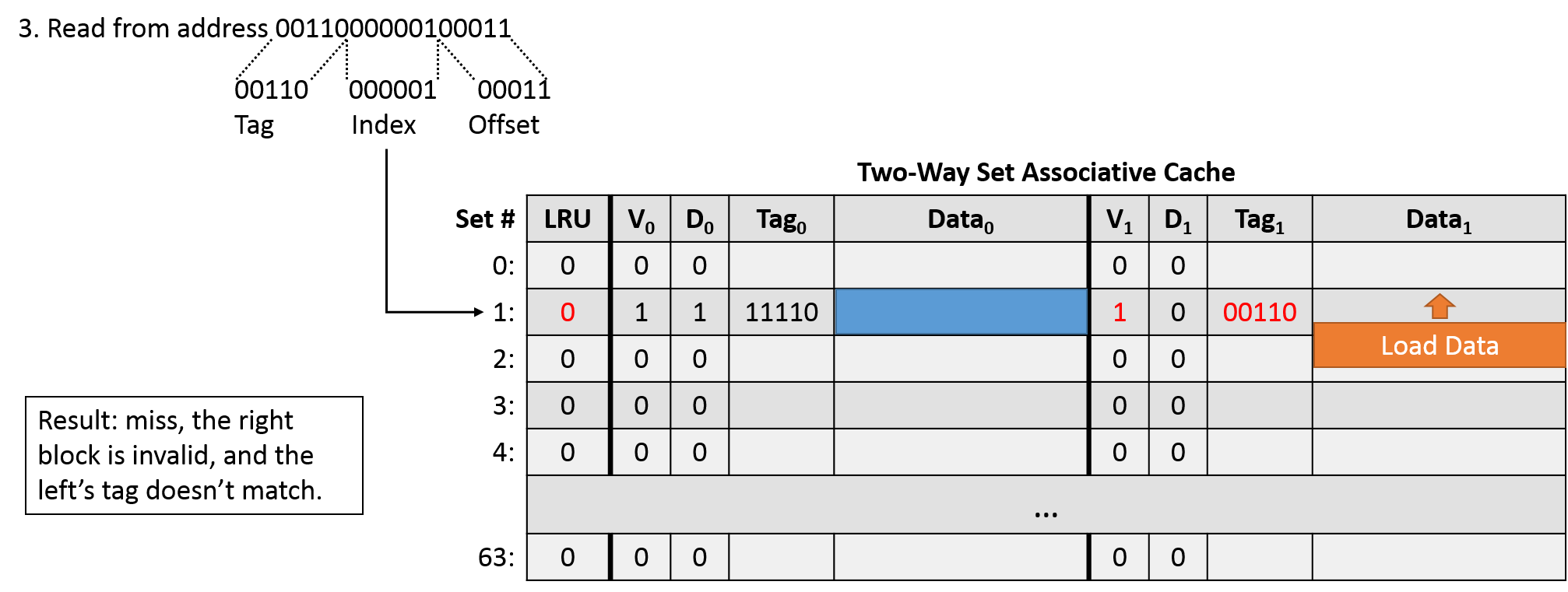
The next access (read 1111000000111111) divides into an offset of 11111, an index of 000001, and a tag of 11110. Indexing into set 1, we find two valid blocks, so we need to check the tag against both of them. Here, the left tag matches, so we have a cache hit. The only change we need to make to the metadata is updating the LRU bit to 1, since now the right block is least recently used.
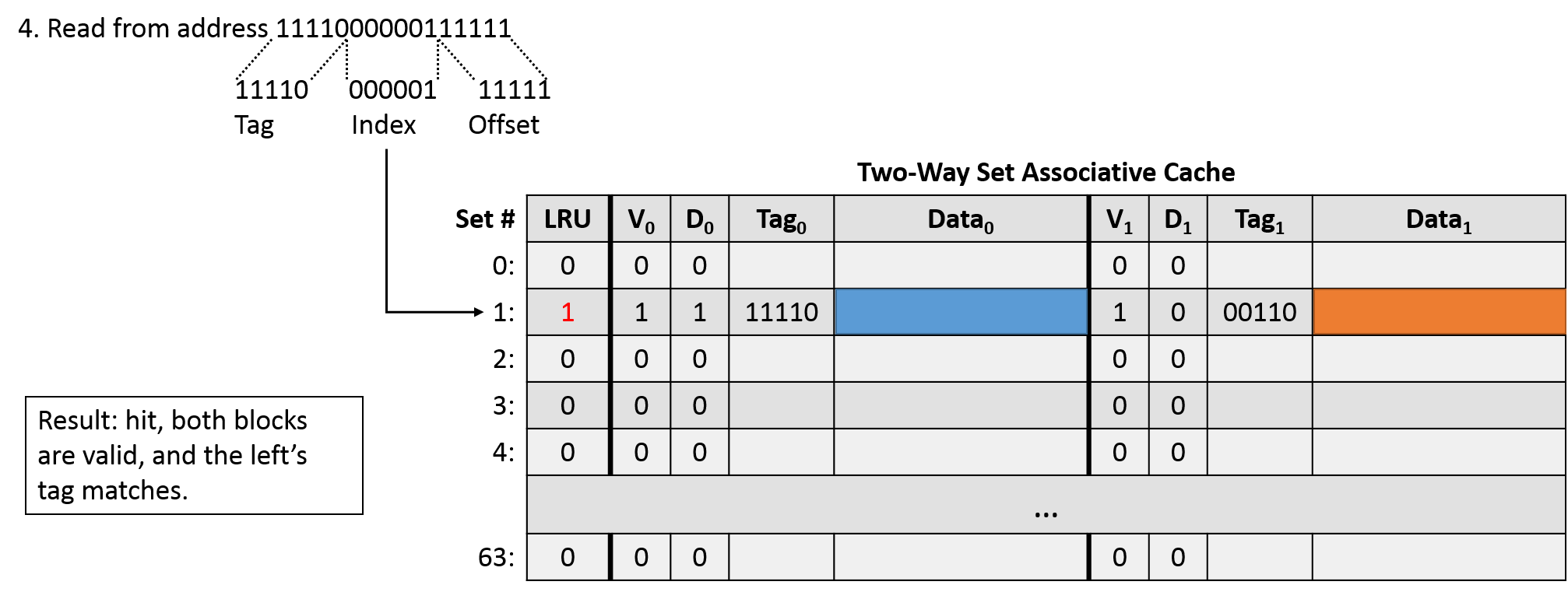
The final access (write 1010100000100000) yields an offset of 00000, an index of 000001, and a tag of 10101. Indexing into set 1, we find two valid blocks, but neither of them have a matching tag. This is a miss, so we need to evict one of the blocks. The LRU bit is currently 1, which indicates we should evict the right block. Since the right block isn't dirty (its contents still match that of memory), we can simply overwrite it with the contents of the new data block. Of course, we need to update the tag to reflect that we changed the data stored in the block, and we need to update the LRU bit to reflect that the left block is now least recently used. Since this operation is a write, we also need to set the dirty bit to 1.
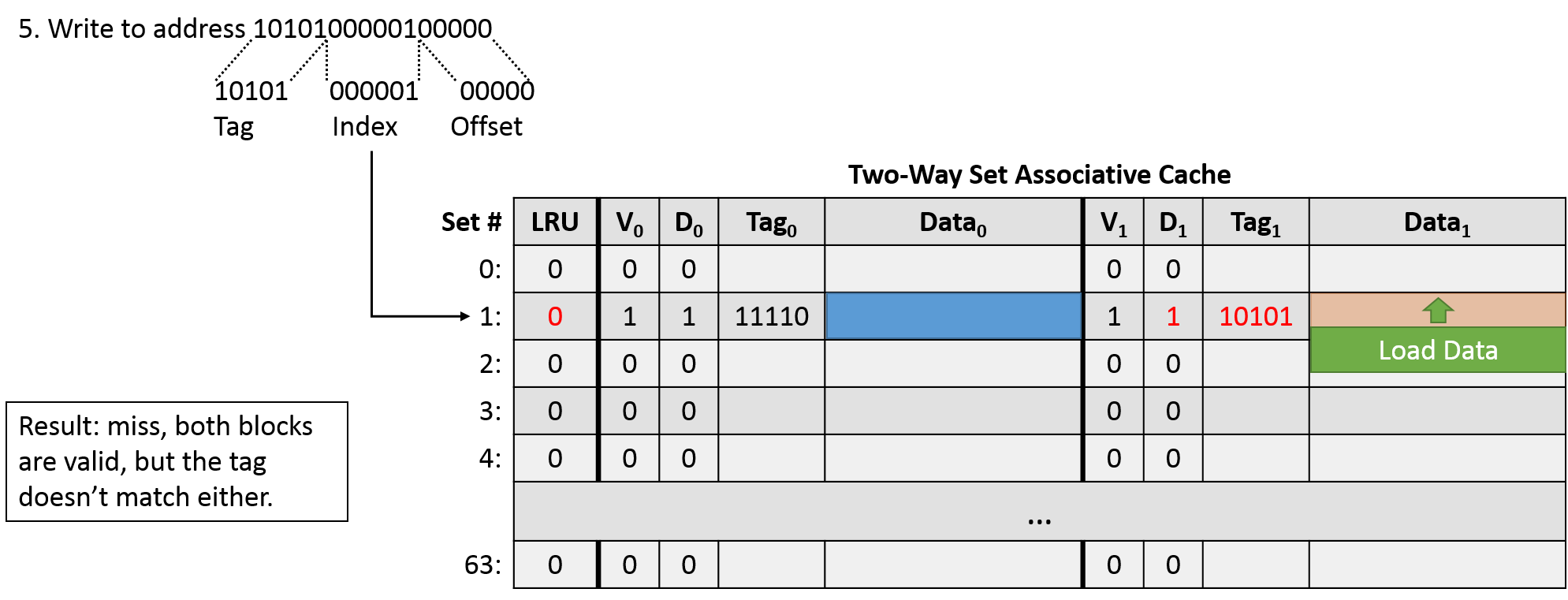
Hopefully these examples have helped to characterize cache behavior. Up next, we'll round out our discussion of caches by exploring the performance implications of caches for programs.